
MySql-深入理解B+树索引
MySql-深入理解B+树索引前言—没有索引的查找在正式介绍 索引 之前,我们需要了解一下没有索引的时候是怎么查找记录的。我们下边先只唠叨搜索条件为对某个列精确匹配的情况,所谓精确匹配,就是搜索条件中用等于 = 连接起的表达式,比如这样:
1SELECT [列名列表] FROM 表名 WHERE 列名 = xxx;
1、在一个页中的查找假设目前表中的记录比较少,所有的记录都可以被存放到一个页中,在查找记录的时候可以根据搜索条件的不同分为两种情况:
以主键为搜索条件
这个查找过程我们已经很熟悉了,可以在 页目录 中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
以其他列作为搜索条件
对非主键列的查找的过程可就不这么幸运了,因为在数据页中并没有对非主键列建立所谓的 页目录 ,所以我们无法通过二分法快速定位相应的 槽 。这种情况下只能从 最小记录 开始依次遍历单链表中的每条记录,然后对比每条记录是不是符合搜索条件。很显然,这种查找的效率是非常低的。
2、在很多页中查找大部分情况下我们表中存放的记录都是非常多的,需要好多的数据页来存储这些记录。在 ...
MySql-深入理解InnoDB数据结构
MySQL-深入理解InnoDB数据结构InnoDB行格式行格式/Row Format简介我们平时是以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为 行格式 或者 记录格式 。
InnooDB目前有四种行格式:
compact(简洁的)
redundant(冗余的)
dynamic(动态的)
compress(压缩的)
创建表时可以指定它的 行格式 :
123456CREATE TABLE record_format_demo ( c1 VARCHAR(10), c2 VARCHAR(10) NOT NULL, c3 CHAR(10), c4 VARCHAR(10)) CHARSET = ascii ROW_FORMAT = COMPACT;
COMPACT行格式
Compact行格式中,一条完整的记录可以被分为 记录的额外信息 和 记录的真实数据 两大部分。
变长字段长度列表MySQL 支持一些变长的数据类型,比如 VARCHAR(M) 、 VARBINARY(M) 、各种 TEXT 类型,各种 BLOB 类型,变长字段中存储多少字节的数据是不固定的 ...

数据库-平滑的节点扩容方案
数据库-平滑的节点扩容方案背景众所周知,数据库很容易成为应用系统的瓶颈。单节点数据库的资源和处理能力有限,在高并发的分布式系统中往往会成为整个业务系统的性能瓶颈,此时可考虑采用分库分表突破单节点局限。本文来探讨下数据库节点的平滑扩容方案。
节点扩容什么是节点扩容数据库扩容一般是指水平分库,也就是当一个业务库无法承载流量压力时,需要对相应的业务拓展数据库的节点数量,但扩容时必须要考虑本次增加节点会不会影响之前的业务数据,因为很多情况下,当数据库节点的数量发生改变时,往往会影响数据分片的路由规则,从而影响数据的读写,这时就要考虑扩容是否会影响原本的路由规则。
数据库扩容一般都是基于水平分库的基础上,进一步对水平库做节点扩容,目前业内有两种主流做法:水平双倍扩容法、异步双写扩容法。
节点扩容的方案传统的双倍扩容法如果增加的节点数和扩容操作没有规划,那么绝大部分数据所属的分片都有变化,需要在分片间迁移,整体的迁移步骤大致如下:
预估迁移耗时,发布停服公告;
停服(用户无法使用服务),使用事先准备的迁移脚本,进行数据迁移;
修改为新的分片规则;
启动服务器。
水平双倍扩容法想要使用双倍扩容法 ...
数据库-全局表
数据库-全局表数据库中全局表是什么?
全局表是一种在数据库中广泛使用的表类型,它通常用于存储在多个数据库实例或节点之间共享的数据。全局表具有数据一致性、分布式访问、高可用性的特点。数据一致性是指全局表中的数据在所有副本中保持一致,这可以通过分布式事务和一致性协议来实现。举例来说,假设一个电商平台在多个地理位置都有服务器,每个服务器都有一个全局表来存储用户信息。通过全局表,任何一个服务器上的用户信息更新都能实时同步到其他服务器,从而确保所有用户在不同地点访问时看到的数据是一致的。这样不仅提高了数据访问的可靠性,还确保了用户体验的一致性。
数据一致性数据一致性是全局表的核心特性之一。在分布式系统中,数据一致性意味着多个节点上的数据副本在任何时刻都保持相同的状态。这一特性通常通过分布式事务和一致性协议来实现。分布式事务是一种能够跨越多个数据库节点的事务机制,确保事务的所有操作要么全部成功,要么全部失败,从而保证数据的一致性。一致性协议(如Paxos、Raft)则是通过一致性算法来协调多个节点之间的数据更新,确保所有节点在数据更新时达成一致。举例来说,当用户在电商平台上更新地址信息时,通过全 ...
数据库-权衡范式与反范式设计
数据库-权衡范式与反范式设计什么是范式设计与反范式设计范式设计(Normalization)定义:
范式设计是数据库设计中最基础的设计原则之一,它主要通过规范化数据模型,减少数据冗余和数据不一致的问题。
常用的范式:
第一范式(1NF):要求数据库中的每个字段都是原子性的,即每个字段都是一个不可再分的数据项。例如,学生的姓名和成绩应分别单独作为一个字段,而不是放在同一个字段中。
第二范式(2NF):要求数据库中的每个非主键字段都完全依赖于主键。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性(针对联合主键),如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。这意味着非主键字段不能依赖于其他非主键字段。例如,在一个课程信息表中,如果学分依赖于学期而不是课程编号,那么就不符合第二范式。
第三范式(3NF):要求数据库中的每个非主键字段都不依赖于其他非主键字段。换句话说,非主键字段之间不应该存在传递依赖关系。例如,在订单信息表中,如果商品价格依赖于商品编号而不是订单号,那么就不符合第三范式。
目的:
消除数据冗余,提高数据的一致性和 ...
MySQL-高效SQL编写建议
高效SQL编写规范建议
SQL编写的一些优化经验:
避免使用SELECT*FROM语句,应该只选择需要的列,以减少网络传输和提高查询性能
使用索引来提高查询速度,特别是在对大型表进行查询时
避免使用外键约束,因为它们可能会导致性能问题,特别是在对大型表进行插入、 更新和删除操作时
使用LIMIT1来限制查询结果只有一条记录
避免在where子句中使用OR采连接条件,应使用UNION来连接查询
注意优化LIMIT深分页问题,可以使用OFFSET来替代LIMIT
使用where条件限制要查询的数据,避免返回多余的行
尽量避免在索引列上使用MySQL的内置函数,这可能导致索引失效
应尽量避免在where子句中对字段进行表达式操作,这可能导致索引失效
应尽量避免在where子句中使用!=或<>操作符,这可能导致索引失效
使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则
1、大批量插入数据如果同时执行大量的插入,建议使用多个值的INSERT语句(方法二)。这比使用分开INSERT语句快(方法一),一般情况下批量插入效率有几倍的差别。
方法一:
123insert into ...

脱敏
自定义脱敏表示注解
12345678910111213141516171819202122@Target({ElementType.FIELD})@Retention(RetentionPolicy.RUNTIME)public @interface Mark { /** * 是否开启,默认开启|可以灵活关闭注解能力 * true:开启 * false:关闭 * * @return */ boolean on() default true; /** * 注解标识字段的脱敏类型 * * @return * @see MarkStrategyEnum 脱敏枚举 */ MarkStrategyEnum markType();}
策略枚举规范接口
1234567public interface IMark { Logger logger = LoggerFactory.getLogger(IMark.class); String mark(St ...
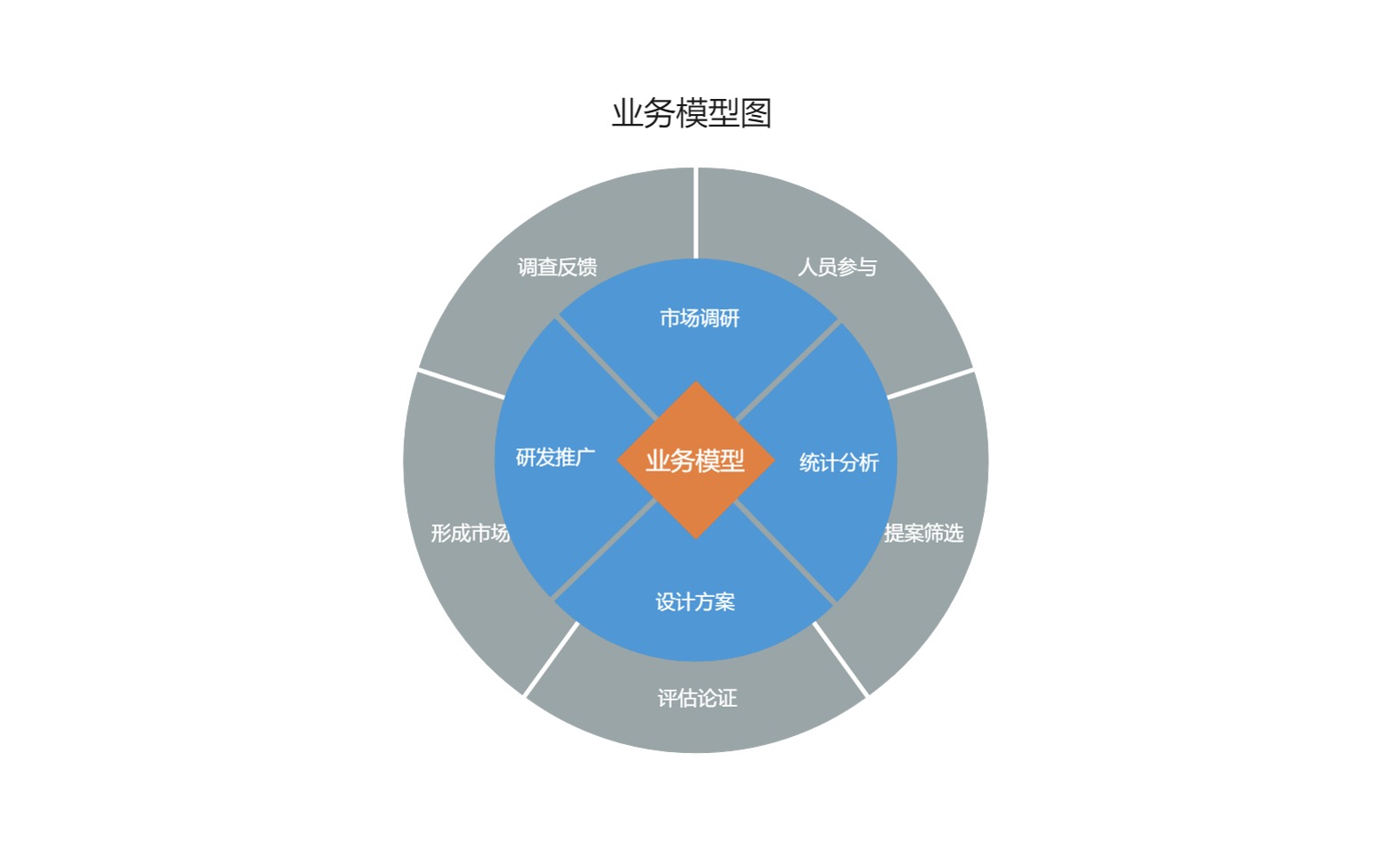
数据模型-业务模型
数据模型-业务模型数据分析模型一般有两种,业务模型和算法模型。
业务模型是基于业务角度的思考,从业务指标和业务维度出发,协助梳理和构建业务规则的指标体系。这些方法一般是一类思想或者是方法论,辅助业务更好地理解当前业务现状。不同行业领域应用的业务模型会有差异。这里举例几个常见的业务模型。
AARRR模型分析AAARR(Aquisition,Activation,Retention,Revenue,Referral)模型是互联网领域常用的分析模型,用来分析用户使用路径和用户流量变化的业务模型。模型将用户分成五个方面进行刻画: 用户获取(Aquisition): 即新客户使用阶段,新客户的获取的方式包含外部广告投放、明星推荐、活动拉新等方式,通常这里需要考虑的信息有新用户注册数量,不同渠道的注册数量和访问数量,不同渠道留存量和用户活跃度 用户激活(Activation): 即新用户获取后,开始在应用中活跃起来,此时需要考虑用户活跃数量 用户留存(Retention):即新用户可以持续在应用中使用,其目的是让用户持续在应用中保持活跃。此时可以考虑用户的流失率、用户转化率 用户变现(Revenu ...

参照源List对目标List进行排序
参照源List对目标List进行排序有两个list列表:list1和list2存储的元素是统一类型,但二者的顺序不一致,现在需要根据其中一个list来排序另外一个list。
123456789101112131415161718192021222324252627282930public static void main(String... str) { List<String> list = new ArrayList<>(); list.add("B"); list.add("D"); list.add("C"); list.add("A"); List<String> list2 = new ArrayList<>(); list2.add("A"); list2.add("C"); list2.add("D"); System.out.println(list2. ...
Java关键字transient
Java关键字transienttransient是一个Java关键字,它主要用于指示JVM在对象序列化过程中,忽略序列化该变量,即不将该变量写入到序列化流中。通过使用transient,可以避免对临时变量和敏感数据的序列化,并提高序列化性能。
在Java语言中,对象的序列化和反序列化是通过实现Serializable接口和Externalizable接口来完成的。在序列化对象时,JVM会将对象转换为二进制流,并将其写入文件或网络流中。如果对象中某个字段被transient修饰,JVM将忽略该字段的序列化。在反序列化对象时,JVM会将二进制流转换回对象,并自动为Transient字段分配默认值。
transient通常用于指定一些临时变量或敏感数据,不希望在序列化时被记录下来。例如,密码、会话令牌或加密密钥等信息就应该被声明为transient字段。另外,如果某些字段不需要在序列化后传递给其他系统,也可以使用transient来避免序列化。
需要说明的是:
transient关键字只能修饰变量,不能修饰方法或类。
序列化和反序列化是针对对象而言的,对于类变量(静态变量,由static ...
数据库-典型场景表设计
数据库–典型场景表设计
配置表设计通过配置表,可以灵活的实现对某些业务场景的配置。比如:开发中某些经常变更的参数值,使用配置。如 订单30分钟后失效,需求变更,要改为15分钟,那么直接改配置表内容就行,不用发版。某些关键的容易出错的逻辑,加上一个开关,比如: config_value 为 0或1,为1表示开,为0表示关。不需要的逻辑,可以及时用开关关掉。或者是逻辑复杂,开发环境造数据麻烦时,也可以用配置表配置开关,把前置条件关掉,方便验证数据。或者通过配置表实现各场景下的处理器组合(即各种职责链)等。
配置表单表设计
1234567891011CREATE TABLE `xxx_config` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '主键', `config_key` varchar(128) NOT NULL COMMENT '配置的KEY', `config_value` varchar(2000) DEFAULT '' COMMENT '配置值', ...
数据库-表设计规范与SQL技巧
数据库-表设计规范与SQL技巧MySQL体系结构
Connectors:用来与客户端应用程序建立连接的数据库接口。Management Services & Utilities:系统管理和服务控制相关的辅助工具。Connection Pool:负责处理与用户访问有关的各种用户登录、线程处理、内存和进程缓存需求。Sql Interface:提供从用户接受命令并把结果返回给用户的机制。Parser:对SQL语句进行语法分析和解析,构造一个用来执行查询的数据结构。Optimizer:优化查询语句,以保证数据检索动作的效率达到或者非常接近最优。使用一种 “选取-投影-联结” 策略来处理查询,即先根据有关的限制条件进行选取(Select 操作)以减少将要处理的元组个数,再进行投影以减少被选取元组的属性字段的个数,最后根据连接条件得到最终的查询结果。Caches & Buffers:保证使用频率最高的数据或结构能够以最有效率的方式被访问,缓存的类型有:表缓存、记录缓存、键缓存、权限缓存、主机名缓存等。
MySQL执行select的流程
1、查询缓存检查查询缓存是否打开,检查是否 ...
Java之Modifier
修饰器 ModifierJava 中常见的修饰器:public、private、protected、static、final、…等等。
Java中的属性、方法、构造器、内部类等等都需要使用修饰器进行修饰,所以通过反射可以获取对应的Field对象、Method对象、等等。
Modifier的源码:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117package java.lang.reflect;import java.security.AccessController;import sun.reflect.ReflectionFactory;import ...

Spring之static属性的自动注入
Spring之static属性的自动注入
结论:Spring不支持static属性的自动注入!
静态属性静态属性和非静态属性的区别:1、在内存中存放位置不同 所有带static修饰符的属性或者方法都存放在内存中的方法区 而非静态属性存放在内存中的堆区2、出现时机不同 静态属性或方法在没创建对象之前就已经存在 而非静态属性在创建对象之后才存在3、静态属性是在某个类中的所有对象是共享的4、生命周期不同 静态属性在类消失之后才销毁 而非静态属性在对象销毁之后就销毁
静态属性在内存中的分布图
Spring依赖注入源码Spring在创建一个bean的时候,还要去填充bean的属性,大致流程如下:
反射创建bean // createBeanInstance
填充bean // populateBean
初始化bean // initializeBean(包括前、后置增强)
注册bean的销毁方法 // registerDisposableBeanIfNecessary
自动注入逻辑在populateBean中:
1234567891 ...
Spring之ApplicationContextAware
Spring之ApplicationContextAware内容概要ApplicationContextAware接口能够轻松感知并在Spring中获取应用上下文,进而访问容器中的其他Bean和资源,这增强了组件间的解耦,增加了代码的灵活性和可扩展性,是Spring框架中实现高级功能的关键接口之一。
核心概念ApplicationContextAware是Spring框架提供的一个特殊的回调接口,用于帮助对象(特别是普通的Java Bean)访问到Spring的应用上下文ApplicationContext。
当在自己的类中实现ApplicationContextAware接口时,可以通过Spring提供的回调机制访问到Spring的应用上下文,从而获得Spring IoC容器中的bean实例、配置信息以及进行国际化操作、事件发布等操作。
在ApplicationContextAware接口中定义了一个setApplicationContext方法,当类实现了该接口之后,Spring IoC容器会自动调用该方法并将当前的ApplicationContext注入到所实现的setAppli ...
数据库-索引表设计
数据库-索引表设计索引表模式基于数据存储中经常由查询引用的字段创建索引。 此模式可让应用程序更快地找到要从数据存储中检索的数据,从而提高了查询性能。
上下文和问题许多数据存储使用主键组织实体集合的数据。 应用程序可以使用此键来查找和检索数据。 下图显示了一个保存客户信息的数据存储示例。 主键为“客户 ID”。 该图显示按主键(“客户 ID”)组织的客户信息。
尽管主键对于基于此键值提取数据的查询很有作用,但如果应用程序需要基于其他某个字段检索数据,则可能无法使用主键。 在客户示例中,如果应用程序只是通过引用其他某个属性(例如,客户所在的城镇)的值查询数据,则无法使用“客户 ID”主键来检索客户。 若要执行此类查询,应用程序可能需要提取并检查每条客户记录,而这是一个缓慢的过程。
许多关系数据库管理系统支持辅助索引。 辅助索引是按一个或多个非主键(辅助键)字段组织的独立数据结构,指示每个索引值的数据的存储位置。 辅助索引中的项通常已按辅助键的值排序,以便快速查找数据。 这些索引通常由数据库管理系统自动维护。
可以根据需要创建任意数目的辅助索引来支持应用程序执行的不同查询。 例如,在关系数 ...

浅析收单业务
收单业务什么是收单业务收单业务, 是指收单机构向商户提供的银行卡交易, 本外币资金结算等服务. 通俗点说, 就是消费者在商户刷卡消费, 收单机构通过银行将消费者的资金在规定周期内结算给商户, 并从中分润一定比例的手续费.
从 《银行卡收单业务管理办法》中银行卡收单业务定义来看, 银行卡收单业务, 是指收单机构与特约商户签订银行卡受理协议,在特约商户按约定受理银行卡并与持卡人达成交易后,为特约商户提供交易资金结算服务的行为。收单业务常规区分线下收单和线上收单;
一般的收单业务涉及的主体分为四类,分别是:持卡人、特约商户、银行、收单机构。
传统卡收单一个典型信息流如下:
涉及的各个角色说明:
持卡用户
就是消费者, 银行借记卡或者信用卡的持有者.
发卡行
发卡行是向持卡人(即用户或消费者)发行各种银行卡,并通过提供各类相关的银行卡服务收取服务费,是银行卡市场的发起者和组织者,是银行卡市场的卖方。
收单机构(银行也可以是收单机构,收单机构为银行时,叫收单行)
负责特约商户的开拓与管理、授权请求、账单结算等活动,其利益主要来源于特约商户交易手续费的分成、服务费。收单机构也可以是第三方收 ...

消息触达
消息触达消息触达是指在应用程序或系统中,将信息传递给用户或其他系统的过程。在云计算领域,消息触达通常涉及到事件通知、消息队列、实时通信等方面。
消息触达的应用场景消息触达在各种应用场景中都有广泛应用,例如:
实时通信:在聊天应用、社交媒体、在线游戏等场景中,需要实时传递消息和通知。
事件驱动架构:在事件发生时,需要通知其他系统或服务。
数据处理:在大数据处理、机器学习等场景中,需要处理大量的实时消息和数据。
消息触达的优势消息触达具有以下优势:
异步通信:消息触达可以实现异步通信,降低系统之间的耦合度。
可扩展性:消息触达可以水平扩展,以满足大量用户和消息的需求。
容错性:消息触达可以保证消息的可靠传递,即使出现故障也不会影响整个系统。
消息触达的分类消息触达可以分为以下几类:
点对点消息:一对一的消息传递。
发布/订阅消息:一对多的消息传递。
消息队列:异步消息传递,可以保证消息的顺序和可靠传递。
参考文档:
消息触达
Git命令
Git命令Git(读音为/gɪt/)是一个开源的分布式版本控制系统,可以有效、高速地处理从很小到非常大的项目版本管理。
Git仓库及命令执行的数据流图
Git常用命令基础命令git init初始化一个Git仓库,在一个目录下执行该指令,表示将该目录初始化成一个Git本地工作区。
git add .添加本地工作区下所有文件添加到到暂存区。
git commit -m xxx将工作区的文件提交至本地仓库,并描述本次提交信息。
git fetch从远程仓库获取最新版本数据到本地仓库,但不会自动merge到暂存区。最常见的场景如取回origin主机的master 分支:
1git fetch origin master
取回更新后,会返回一个FETCH_HEAD ,指的是fetch的branch在服务器上的最新状态,我们可以在本地通过它查看刚取回的更新信息:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162 ...

白话DDD入门
白话DDD入门
一个维护中的业务系统引出的思考这几年维护的一个带货类的项目,这个项目用了最传统的三层模型来搭建,大概是如下的模型:
当这个项目维护几年之后,逐渐出些了一些有意思的情况,如下:
情况 1(代码层面):少部分代码可读性在长期不同人员的修改下变得越来越差。如:某个带货的核心 rpc 逻辑没有任何嵌套,平铺在一个函数里,单函数代码行数达到几百行,可读性和维护性极差,成功化身为“技术护城河”。
情况 2(微服务层面): 某些微服务初始职能划分较为简单,导致少量模块在后续快速的迭代中迅速膨胀。如:其中的 mp 模块,原本职能是用来承接 B 端门户的功能,当我们决定拆分这个庞大的模块时,这个模块已经承载了 204 个 rpc。过多的能力承担让它编译变慢、变成链路单点、改动较多、一旦出现问题影响较大。
情况 3(业务团队层面):带货项目会使用一些其他业务系统的接口和数据结构,当这些业务系统想要修改这些接口和数据结构的时候 ,偶尔可能没有察觉这里的依赖导致线上问题, 或者沟通过来发现耦合处比较多不容易改动。
对这个项目的维护引出了一些思考,在一个复杂业务系统中:代码结构要如何设计、微 ...